A new study from the Thompson Lab, led by Harvard Forest Research Assistant Lucy Lee, evaluated 27 publicly available data products that quantify the distribution of “forests” across the conterminous United States. They found that these tools’ estimates of the total land area of forest ecosystems differed by over 2,000,000 km2.
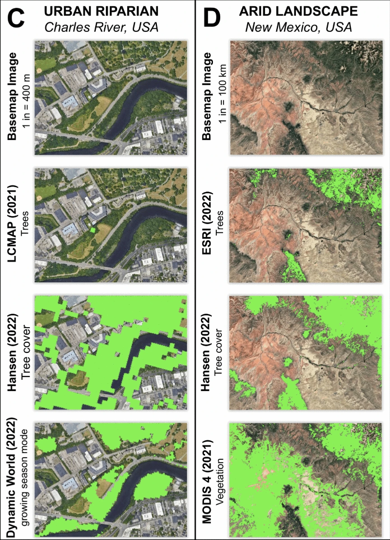
One example the authors offer is that, depending on the public dataset used, someone wishing to understand the status of forests in the U.S. might reasonably conclude that 81,991 km2 of forest have been lost over the past 30 years – but could just as reasonably conclude that 93,536 km2 has been gained.
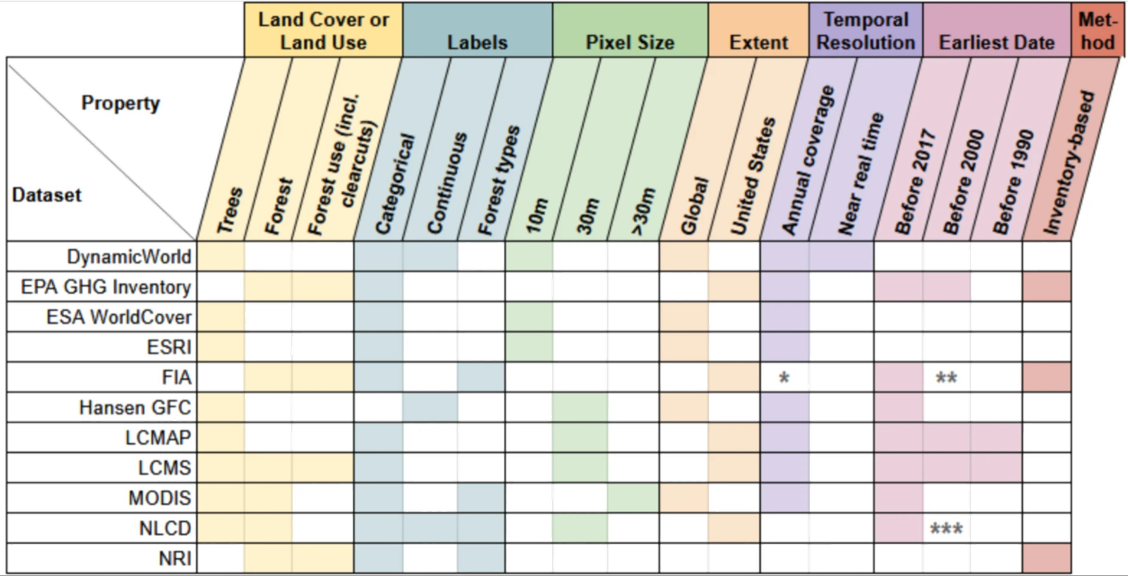
The authors urge caution to researchers and practitioners in selecting a dataset, because the characteristics of the datasets vary widely (including the time resolution used to gather the data, and the threshold at which a pixel is considered “forest”).
Lucy Lee, co-lead author of the study, explains: “Intuitively, we understand what a ‘forest’ is when we are in one. So, when we see a map labeled ‘forest’, it is easy to assume that the map matches up with our expectations of what a forest is. But there are many factors, both technical and conceptual, that lead maps of ‘forest’ to be different and sometimes surprising. Today, people have many choices in what forest maps they use, and we wanted to highlight the differences between them and give people tools to choose the best data for their needs.”
The most appropriate dataset to use, the authors suggest, depends on the question the data is intended to answer, and also may require the use of statistical methods to correct biases in map-based estimates.
They developed a public tool for quick reference to help users understand the assumptions and characteristics behind forest datasets, and which one may be best suited to their question. They have also published their processing code so the comparative tool can be used in other regions.
This work was by the National Science Foundation (DEB-LTER-18-32210).